

درختهای تصمیم یکی از الگوریتمهای یادگیری ماشینی محبوبی هستند که میتوان از آن برای کارهای رگرسیون و طبقهبندی استفاده کرد. درک، تفسیر و پیادهسازی درخت تصمیم آسان است و همین، آن را به انتخابی ایدهآل برای مبتدیان در زمینه یادگیری ماشین تبدیل میکند.
در این مقاله، تمام جنبههای الگوریتم درخت تصمیم، از جمله اصول کار، انواع درختهای تصمیم، فرایند ساخت درختهای تصمیم، و نحوه ارزیابی و بهینهسازی آنها را پوشش خواهیم داد. در پایان این مقاله، درک کاملی از درخت تصمیم، مثالها و نحوه استفاده از آنها برای حل مسائل دنیای واقعی خواهید داشت. با ما همراه باشید.
درخت تصمیم چیست؟
درخت تصمیم یا Decision Tree، یک الگوریتم یادگیری نظارت شده و غیرپارامتریک است که برای انجام کارهای طبقهبندی و رگرسیون استفاده میشود. درخت تصمیم یک مدل سلسلهمراتبی است که به عنوان یک پشتیبان برای تصمیمگیری، تصمیمها و نتایج بالقوه آنها را به تصویر میکشد که میتواند شامل رویدادهای شانسی، هزینههای منابع و کاربردها باشد. ساختار درختی از یک گره ریشه، شاخهها، گرههای داخلی و گرههای برگ تشکیل شده است که ساختاری سلسلهمراتبی و درخت مانند را تشکیل میدهد.
همانطور که در نمودار زیر مشاهده میکنید، درخت تصمیم با یک گره ریشه شروع میشود که هیچ شاخه ورودی ندارد. سپس شاخههای خروجی از گره ریشه، وارد گرههای داخلی میشوند که به عنوان گرههای تصمیم نیز شناخته میشوند. بر اساس ویژگیهای موجود؛ هر دو نوع گره، ارزیابیهایی را برای تشکیل زیرمجموعههای همگن انجام میدهند که با گرههای برگ یا گرههای پایانی مشخص میشوند. در نهایت گرههای برگ، همه نتایج ممکن را در مجموعه داده نشان میدهند.
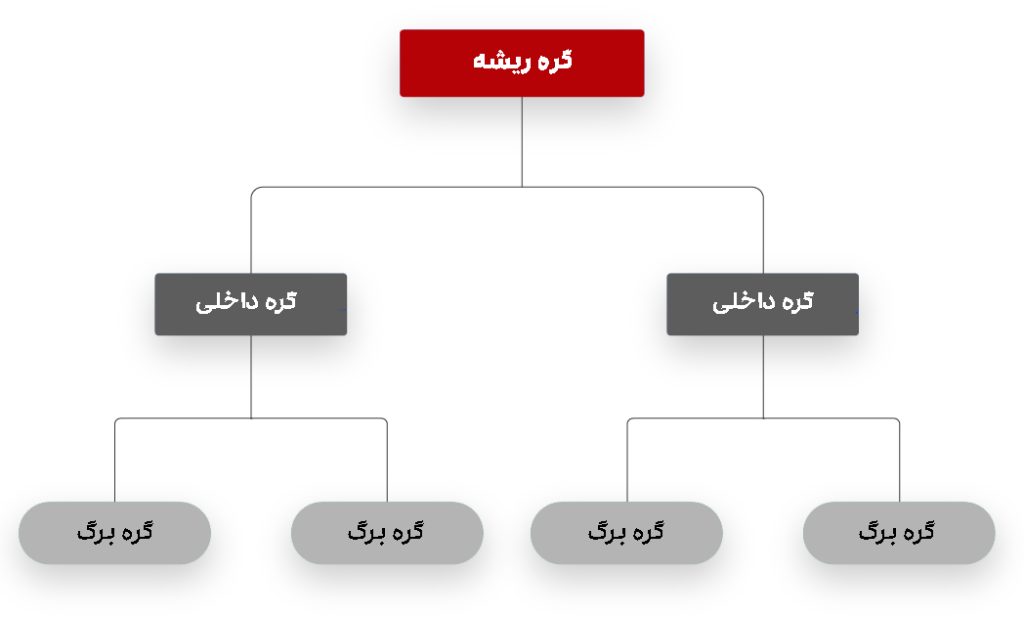
نمونه ساختار و اجزای درخت تصمیم
این نوع ساختار نموداری یا فلوچارتی، یک نمایش ساده برای گزینههای موجود بابت تصمیمگیری ایجاد میکند و به گروههای مختلف در سراسر یک سازمان اجازه میدهد تا درک بهتری از چرایی تصمیمگیری داشته باشند.
درخت تصمیم ابزاری است که در حوزههای مختلف کاربرد دارد. از این الگوریتم میتوان برای طبقهبندی و همچنین مشکلات رگرسیون استفاده کرد. درواقع نام این الگوریتم نشان میدهد که از یک فلوچارت ساختار درختی، برای نشاندادن پیشبینیهای حاصل از یک سری تقسیمبندیهای مبتنی بر ویژگی استفاده میکند؛ با یک گره ریشه شروع میشود و با تصمیمگیری توسط برگها به پایان میرسد. درختان تصمیم ابزار محبوب و قدرتمندی هستند که در زمینههای مختلفی مانند یادگیری ماشینی، داده کاوی و آمار استفاده میشوند. این الگوریتم با مدلسازی روابط میان متغیرهای مختلف، راهی روشن و شهودی را برای تصمیمگیری بر اساس دادهها ارائه میدهند.
از کاربردهای درخت تصمیم در کسبوکار میتوان به موارد زیر اشاره کرد:
- تصمیمگیری تجاری: در برنامهریزی استراتژیک و تخصیص منابع استفاده میشود،
- مراقبتهای بهداشتی: به تشخیص بیماریها و پیشنهاد برنامههای درمانی کمک میکند،
- امور مالی: به امتیازدهی اعتبار و ارزیابی ریسک کمک میکند،
- بازاریابی: برای تقسیمبندی مشتریان و پیشبینی رفتار مشتری استفاده میشود.
مهمترین اصطلاحات درخت تصمیم
پیش از معرفی بیشتر Decision Tree، بهتر است با برخی از اصطلاحات درخت تصمیم آشنا شوید:
- گره ریشه (Root Node): اولین گره در ابتدای درخت تصمیم، جایی که پس از آن، کل جمعیت یا مجموعه داده بر اساس ویژگیها یا شرایط مختلف، تقسیم میشود،
- گره تصمیم (Decision Node): گرههای حاصل از تقسیم گره ریشه، به عنوان گرههای تصمیم شناخته میشوند. این گرهها تصمیمات یا شرایط میانی در درخت را نشان میدهند،
- گره برگ (Leaf Node): گرههایی که در آنها تقسیم بیشتر امکانپذیر نیست. گرههای برگ که به عنوان گرههای پایانی نیز شناخته میشوند، اغلب نشاندهنده طبقهبندی یا نتیجه نهایی هستند،
- درخت فرعی (Sub-Tree): مشابه زیربخشی از یک گراف که گراف فرعی نامیده میشود، زیرمجموعهای از درخت تصمیم به عنوان درخت فرعی شناخته میشود که نشاندهنده بخش خاصی از Decision Tree است،
- هرس (Pruning): فرایند حذف یا قطع گرههای خاص در درخت تصمیم برای جلوگیری از برازش بیش از حد و سادهسازی مدل را هرس مینامند،
- شاخه (Branch): شاخه، زیربخشی از کل درخت تصمیم است که یک مسیر خاص از تصمیمات و نتایج را درون درخت نشان میدهد،
- گره والد و فرزند (Parent and Child Node): در درخت تصمیم، گرهای که به گرههای فرعی تقسیم میشود، به عنوان گره والد شناخته میشود و گرههای فرعی که از آن بیرون میآیند، گرههای فرزند هستند. گره والد بیانگر یک تصمیم یا شرط است، درحالیکه گرههای فرزند نشاندهنده نتایج بالقوه یا تصمیمات بعدی بر اساس آن شرایط هستند.
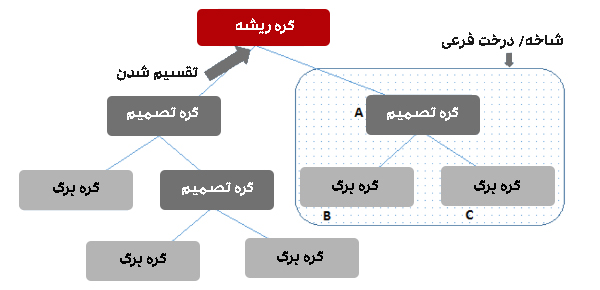
نمایش اجزای درخت تصمیم
مهمترین مفروضات درخت تصمیم
هنگام ایجاد درختهای تصمیم، برای ساختن مدلهای مؤثر چندین فرض وجود دارد که به ساخت درخت کمک کرده و بر عملکرد آن تأثیر میگذارد. در ادامه برخی از مفروضات و ملاحظات رایج هنگام ساخت درخت تصمیم معرفی شدهاند.
- تقسیمهای باینری یا دوتایی (Binary Splits): درختهای تصمیم معمولاً تقسیمهای باینری ایجاد میکنند؛ به این معنا که هر گره داده، بر اساس یک ویژگی یا شرایط واحد، به دو زیر مجموعه تقسیم میشود. این فرض نشان میدهد که هر تصمیم میتواند به عنوان یک انتخاب با دو نتیجه نمایش داده شود.
- تقسیمبندی بازگشتی (Recursive Partitioning): درختهای تصمیم از یک فرایند تقسیمبندی بازگشتی استفاده میکنند که در آن، هر گره به گرههای فرزند تقسیم میشود و این فرایند تا زمانی ادامه پیدا میکند که یک معیار توقف برآورده شود. این فرض بیان میکند که دادهها را میتوان به طور مؤثر، به زیر مجموعههای کوچکتر و قابلمدیریتتر تقسیم کرد.
- استقلال ویژگی (Feature Independence): درختهای تصمیم اغلب بر این فرض هستند که ویژگیهای مورد استفاده برای تقسیم گرهها، از یکدیگر مستقل هستند. اگرچه در عمل ممکن است این استقلال برقرار نباشد، اما در صورت وجود همبستگی میان ویژگیها، درختهای تصمیم همچنان میتوانند عملکرد خوبی داشته باشند.
- همگن بودن (Homogeneity): هدف درختان تصمیم ایجاد زیرگروههای همگن در هر گره است، به این معنی که نمونههای درون یک گره تاحدامکان از نظر متغیر هدف مشابه هستند. این فرض به دستیابی به مرزهای تصمیم روشن کمک میکند.
- رویکرد حریصانه از بالابهپایین (Top-Down Greedy Approach): درختهای تصمیم با استفاده از یک رویکرد حریصانه از بالابهپایین ساخته میشوند؛ جایی که هر تقسیم برای به حداکثر رساندن اطلاعات یا بهحداقلرساندن ناخالصی در گره فعلی انجام میشود. این فرض ممکن است همیشه به یک درخت بهینه جهانی منجر نشود.
- ویژگیهای دستهبندی و عددی (Categorical and Numerical Features): درختهای تصمیم میتوانند ویژگیهای دستهبندی و ویژگیهای عددی را مدیریت کنند. بااینحال، آنها ممکن است برای هر نوع، به استراتژیهای تقسیم متفاوتی نیاز داشته باشند.
- برازش بیش از حد (Overfitting): درختهای تصمیمگیری زمانی که نویز را در دادهها ثبت میکنند، مستعد برازش بیش از حد هستند. برای رسیدگی به این فرض از هرس و تعیین معیارهای توقف مناسب استفاده میشود.
- معیارهای ناخالصی (Impurity Measures): درختان تصمیمگیری از معیارهای ناخالصی مانند ناخالصی جینی یا آنتروپی برای ارزیابی میزان جداسازی گرهها توسط یک عامل تقسیم استفاده میکنند؛ بنابراین انتخاب معیار ناخالصی میتواند بر ساخت درخت تأثیر بگذارد.
- نبود ارزشهای گمشده (No Missing Values): درختهای تصمیم بر این فرض هستند که هیچ مقدار گمشدهای در مجموعه داده وجود ندارد یا مقادیر گمشده، به طور مناسب و از طریق انتساب یا روشهای دیگر، مدیریت شدهاند.
- اهمیت برابر ویژگیها (Equal Importance of Features): درختان تصمیم معمولاً برای همه ویژگیها اهمیت یکسانی قائل هستند، مگر اینکه برای تأکید بر ویژگیهای خاص، مقیاسبندی یا وزندهی خاصی اعمال شود.
- نبود داده پرت (No Outliers): درختان تصمیم به نقاط پرت حساس هستند و مقادیر شدید از آنها میتواند بر ساخت درخت تأثیر بگذارند. به همین دلیل برای مدیریت مؤثر دادههای پرت، ممکن است به پیشپردازش یا روشهای قدرتمند دیگر نیاز باشد.
- حساسیت به حجم نمونه (Sensitivity to Sample Size): مجموعهدادههای کوچک ممکن است منجر به برازش بیش از حد شوند و مجموعه کلان داده ها میتوانند درختانی بیش از حد پیچیده ایجاد کنند؛ بنابراین اندازه نمونه و عمق درخت باید متعادل باشد.
انواع الگوریتمهای درخت تصمیم
الگوریتم هانت (Hunt’s algorithm) که در دهه 1960 برای مدل سازی یادگیری انسان در روانشناسی توسعه یافت، پایه و اساس بسیاری از الگوریتمهای محبوب درخت تصمیمگیری را تشکیل میدهد. الگوریتمهای تصمیمگیری معمولا با گام های سادهای کار میکنند که میتوان آنها را در چهار گام درنظر گرفت:
- شروع از ریشه: الگوریتم درخت تصمیم از بالای درخت که “گره ریشه” نامیده میشود، شروع کرده و کل مجموعه داده را نشان میدهد،
- پرسیدن بهترین سؤالات: این الگوریتم به دنبال مهمترین ویژگی یا سؤالی است که بتواند بر مبنای آن، دادهها را به متمایزترین گروهها تقسیم کند؛ مانند پرسیدن یک سوال در یک شاخه درخت،
- هرسکردن: بر اساس پاسخ به سؤالات گام قبل، دادهها به زیرمجموعههای کوچکتر تقسیم شده و شاخههای جدیدی ایجاد میشود؛ هر شاخه نشاندهنده یک مسیر در درخت است.
- تکرار فرایند: الگوریتم درخت تصمیم تا زمانی به پرسیدن سؤالات و تقسیم دادهها در هر شاخه ادامه میدهد که به «گرههای برگ» نهایی برسد که نشاندهنده نتایج یا طبقهبندیهای پیشبینی شده هستند.
از مهمترین الگوریتمهای درخت تصمیم میتوان به موارد زیر اشاره کرد:
الگوریتم ID3
ID3، مخفف “Iterative Dichotomiser 3” است که از آنتروپی و بهدستآوردن اطلاعات به عنوان معیارهایی برای ارزیابی تقسیمات استفاده میکند.
الگوریتم C4.5
این الگوریتم به عنوان تکرار بعدی ID3 در نظر گرفته میشود که توسط کوینلان نیز توسعه داده شد. این الگوریتم میتواند از نسبتهای افزایش اطلاعات، برای ارزیابی نقاط تقسیم در درختهای تصمیم استفاده کند.
الگوریتم CART
اصطلاح CART مخفف «classification and regression trees»، به معنای «درخت طبقهبندی و رگرسیون» است که توسط لئو بریمن معرفی شده است. این الگوریتم معمولاً از ضریب ناخالص جینی برای شناسایی ویژگی مناسب برای تقسیم استفاده میکند. این ضریب اندازهگیری میکند که هر چند وقت یکبار، یک ویژگی تصادفی ممکن است اشتباه طبقهبندی شود. هنگام ارزیابی با استفاده از ضریب ناخالص جینی؛ مقدار کمتر، ایدهآلتر است.
مزایا و معایب الگوریتمهای درخت تصمیمگیری
اگرچه درختهای تصمیم را میتوان در موارد مختلف استفاده کرد، اما الگوریتمهای دیگری نیز وجود دارند که از آنها بهتر عمل میکنند. همانطور که گفته شد، درختهای تصمیم بهویژه برای داده کاوی و موارد مربوط به کشف دانش، مفید هستند. در ادامه به بررسی مزایا و چالشهای کلیدی استفاده از درختهای تصمیم پرداخته شده است.
مزایای درخت تصمیم
- تفسیر آسان: منطق دوتایی و نمایش بصری درختان تصمیمگیری، درک و کاربرد آنها را آسانتر میکند. همچنین ماهیت سلسلهمراتبی یک درخت تصمیم، تشخیص مهمترین ویژگیها را آسان میکند که این موضوع در الگوریتمهای دیگر مانند شبکههای عصبی، همیشه واضح نیست.
- نیاز کم یا عدم نیاز به آمادهسازی داده: درختهای تصمیم دارای ویژگیهایی هستند که آن را نسبت به سایر الگوریتمهای طبقهبندی، انعطافپذیرتر میکند؛ Decision Tree میتواند انواع مختلف داده را مدیریت کند. برای مثال، مقادیر گسسته یا پیوسته داده را میتوان با استفاده از تعیین آستانهها، به مقادیر قابلدستهبندی تبدیل کرد. علاوه بر این، میتوان با این الگوریتم، مقادیر گمشده را نیز مدیریت کرد؛ قابلیتی که برای طبقهبندیکنندههای دیگر مانند Naïve Bayes میتواند مشکلساز باشد.
- انعطافپذیری: درختهای تصمیمگیری را به سبب انعطافپذیری که دارند، میتوان برای کارهای طبقهبندی و رگرسیون به کاربرد. این الگوریتم نسبت به روابط اساسی میان صفات حساس نیست؛ بدان معنی که اگر دو متغیر بهشدت همبستگی داشته باشند، الگوریتم تنها یکی از ویژگیها را برای تقسیم آنها انتخاب میکند.
معایب درخت تصمیم
- مستعد برازش بیش از حد: درختان تصمیم پیچیده، تمایل به برازش بیش از حد دارند و بهخوبی به دادههای جدید تعمیم پیدا نمیکنند. اگرچه با استفاده از فرایندهای پیش هرس یا پس هرس، میتوان از این موضوع اجتناب کرد. پیش هرس، رشد درخت را در زمانی که دادههای کافی وجود ندارد، متوقف میکند. درحالیکه در پس هرس، پس از ساخت درخت، درختان فرعی با دادههای ناکافی حذف میشود.
- واریانس بالا در تغییرات: تغییرات کوچک در دادهها، میتواند درخت تصمیمگیری بسیار متفاوتی ایجاد کند. برای کاهش واریانس در درخت تصمیم میتوان از روشهایی مانند بستهبندی یا میانگینگیری تخمینها استفاده کرد. بااینحال، این رویکرد محدود است؛ زیرا میتواند منجر به ظهور پیشبینیکنندههای بسیار همبسته شود.
- هزینه بالا: ازآنجاکه الگوریتمهای درختان تصمیم در فرایند ساختوساز درخت، رویکرد جستجوی حریصانه ای دارند، آموزش آنها در مقایسه با الگوریتمهای دیگر پرهزینهتر است.
مثال برای درخت تصمیمگیری
برای درک بهتر الگوریتم درخت تصمیمگیری، مثال زیر را بررسی میکنیم.
| روز | وضعیت آب و هوا | دمای هوا | رطوبت | باد | بازی کردن؟ |
| 1 | آفتابی | گرم | بالا | ضعیف | خیر |
| 2 | ابری | گرم | بالا | ضعیف | بله |
| 3 | آفتابی | متعادل | نرمال | قوی | بله |
| 4 | ابری | متعادل | بالا | قوی | بله |
| 5 | بارانی | متعادل | بالا | قوی | خیر |
| 6 | بارانی | خنک | نرمال | قوی | خیر |
| 7 | بارانی | متعادل | بالا | ضعیف | بله |
| 8 | آفتابی | گرم | بالا | قوی | خیر |
| 9 | ابری | گرم | نرمال | ضعیف | بله |
| 10 | بارانی | متعادل | بالا | قوی | خیر |
مثال درخت تصمیمگیری
همانطور که در بخشهای قبل گفته شد، درختان تصمیم وارونه هستند؛ ریشه در بالا قرار دارد و سپس ریشه به چندین گره مختلف تقسیم میشود. درواقع درختهای تصمیم چیزی جز مجموعهای از گزارههای if-else در اصطلاح عامیانه نیستند که پس از بررسی درست یا غلطبودن یک شرط، به گره بعدی متصل به آن تصمیم میرود.
هدف درخت زیر، تصمیمگیری در خصوص بازیکردن یا نکردن، در هر شرایط آبوهوایی است؛ بنابراین ابتدا این سؤال پرسیده میشود که آبوهوا چیست؟ آیا هوا آفتابی، ابری یا بارانی است؟ اگر بله به ویژگی بعدی که رطوبت و باد است میرود. دوباره بررسی میکند که باد شدیدی میوزد یا ضعیف، اگر باد ضعیفی است و بارانی است، ممکن است فرد برود و بازی کند.

نمونه درخت تصمیمگیری
آیا در نمودار بالا متوجه چیزی شدید؟ طبق این درخت تصمیم، اگر هوا ابری باشد، تصمیم نهایی بازی کردن است. اما چرا نمودار در این قسمت بیشتر تقسیم نشد؟ چرا در حالت ابری سریع متوقف شد؟
برای پاسخ به این سوال، باید در مورد مفاهیم دیگر مانند آنتروپی، افزایش اطلاعات و شاخص جینی اطلاعات داشته باشیم. اما به زبان ساده، میتوان گفت خروجی مجموعه داده آموزشی این الگوریتم برای هوای ابری، همیشه بله بوده است، زیرا در دادهها بینظمی وجود ندارد و نیازی به تقسیم بیشتر گره نیست.
درخت تصمیم در یادگیری ماشین
درخت تصمیم در یادگیری ماشین یک الگوریتم همهکاره و قابل تفسیر است که برای مدلسازی پیشبینیکننده استفاده میشود. درواقع نوعی الگوریتم یادگیری نظارت شده است که معمولاً در یادگیری ماشینی برای مدلسازی و پیشبینی نتایج بر اساس دادههای ورودی استفاده میشود. این ساختار درخت مانند، هر گره داخلی را بر حسب یک ویژگی آزمایش میکند، هر شاخه مربوط به مقدار ویژگی است و هر گره برگ بیانگر تصمیم یا پیشبینی نهایی است. الگوریتم درخت تصمیم در دسته یادگیری نظارت شده قرار میگیرد و میتوان از آنها برای حل مسائل رگرسیون و طبقهبندی استفاده کرد.
درخت تصمیم به دلایل مختلف، در یادگیری ماشین به طور گسترده مورد استفاده قرار میگیرد:
- به دلیل قابلیت تفسیر و تطبیقپذیری، در شبیهسازی فرایندهای تصمیمگیری پیچیده قابلیتهای متنوعی ارائه میدهند،
- ساختار سلسلهمراتبی Decision Tree، امکان بهتصویرکشیدن سناریوهای انتخاب پیچیده که دلایل و پیامدهای مختلفی را در نظر میگیرند، فراهم میکند،
- بینش قابلقبولی را در مورد منطق هر تصمیم ارائه میدهند و به همین دلیل، بهویژه برای کارهای شامل طبقهبندی و رگرسیون، مفید هستند.
- برای هر دو نوع دادههای عددی و تفسیری کاربرد دارند و به لطف قابلیت انتخاب مستقل، بهراحتی میتوانند با مجموعههای مختلف داده تطبیق پیدا کنند،
- تجسم سادهای را ارائه میدهند که به درک و روشنشدن فرایندهای تصمیمگیری اساسی در یک مدل کمک میکند.
نرم افزار هوش تجاری، راهکاری برای نمایش هرچه بهتر داده ها
همانطور که در این مقاله به آن اشاره شد، درختهای تصمیم، ابزاری کلیدی در یادگیری ماشین، مدلسازی و پیشبینی نتایج بر اساس دادههای ورودی هستند. این الگوریتم ها قابلیت تفسیر، تطبیق پذیری و تجسم ساده را ارائه می دهند که همین موضوع، آنها را برای کارهای طبقه بندی و رگرسیون ارزشمند می کند.
نرم افزار BI همکاران سیستم با جمعآوری، تحلیل، تبدیل و تفسیر دادهها و تبدیل آن به اطلاعات قابل درک و اعتماد، به کسب و کارها کمک میکند تا با تصمیمگیریهای استراتژیک و هوشمندانه، حضور موثرتری در بازار داشته باشند. در این راهکار تعداد قابل توجهی از داشبوردهای تحلیلی به شکل پیشفرض قابل استفاده هستند که با کمک آنها میتوان دید جامعی نسبت به فرایندهای سازمان کسب کرد.
منابع
- ibm.com
- geeksforgeeks.org
- analyticsvidhya.com


