در عصر اطلاعات امروز، داده پادشاه است. هر روز حجم غیرقابلتصوری از داده ها تولید میشود؛ از تعاملات انجام شده در رسانههای اجتماعی و خریدهای آنلاین تا تحقیقات علمی و الگوهای آبوهوا. این دریای وسیع و همیشه درحالرشد اطلاعات، همان چیزی است که آن را «کلان داده» مینامیم.
کلان داده را میتوان مجموعهای از داده های عظیم و پیچیده دانست که بهخاطر حجم، تنوع و سرعت تولید، ابزارهای پردازش داده سنتی، قادر به جمعآوری، ذخیره، مدیریت یا تجزیهوتحلیل مؤثر آنها نیستند. اما بیگ دیتا چیزی بیشتر از حجم عظیمی از اطلاعات است که پتانسیل ایجاد انقلاب در هر جنبه از زندگی را دارد.
در این مقاله به بررسی دنیای شگفتانگیز دادههای بزرگ میپردازیم. بررسی تاریخچه کلان داده، ویژگیهای آن، معماری بیگ دیتا، کاربردهای کلان داده در کسبوکار، چالشهایی که ارائه میدهد و فرصتهای باورنکردنی که ایجاد میکند را بررسی میکنیم. در نهایت، هدف این مقاله ارائه یک درک جامع از کلان داده و پتانسیلی است که برای ایجاد دنیایی آگاهتر، کارآمدتر و مرتبطتر دارد. با ما همراه باشید.
بیگ دیتا چیست؟
کلان داده ترکیبی از داده های ساختاریافته، نیمهساختاریافته و بدون ساختار است که سازمانها برای رسیدن به اطلاعات و بینش، نسبت به جمعآوری، تجزیهوتحلیل و استخراج آنها اقدام میکنند. از بیگ دیتا میتوان در پروژههای یادگیری ماشین، مدلسازی پیشبینی و دیگر برنامههای کاربردی تجزیهوتحلیل پیشرفته نیز استفاده کرد.
کلان دادهها از منابع بسیاری از جمله سیستمهای پردازش تراکنش، پایگاههای اطلاعاتی مشتریان، اسناد، ایمیلها، سوابق پزشکی، گزارشهای جریان کلیک اینترنتی، برنامههای موبایل و شبکههای اجتماعی به دست میآیند. همچنین شامل دادههای تولید شده توسط ماشین، مانند فایلهای گزارش شبکه و سرور و دادههای حسگر از ماشینهای تولیدی، تجهیزات صنعتی و دستگاههای اینترنت اشیا است.
علاوه بر دادههای سیستمهای داخلی، کلان داده اغلب دادههای خارجی در مورد مصرفکنندگان، بازارهای مالی، شرایط آبوهوایی و ترافیک، اطلاعات جغرافیایی، تحقیقات علمی و موارد دیگر را در خود جای میدهد. تصاویر، ویدئوها و فایلهای صوتی نیز اشکالی از بیگ دیتا هستند که به طور مداوم پردازش و جمعآوری میشوند.
تاریخچه کلان داده
ریشههای کلان داده در دنیا، به طرز شگفتآوری عمیق است. اگرچه ظهور این اصطلاح به حدود سال 2005 برمیگردد، اما تلاش برای مدیریت و استفاده از مجموعهدادههای عظیم، سابقه طولانیتری دارد که به قرن بیستم مربوط میشود. درواقع میتوان تلاشهای اولیه مانند توسعه کارتپانچها و رایانههای کدشکن (code-breaking computers) در جنگ جهانی دوم را پایهای برای ظهور ابزارهای پردازش داده دانست که برای مدیریت اطلاعات درحالرشد دنیای امروز، ضروری هستند.
در ادامه، خلاصهای از تاریخچه بیگ دیتا از سال 1930 تا امروز آورده شده است:
آثار اولیه (1930-1960)
- دهه 1930: ایالات متحده آمریکا با یک پروژه کلان داده مواجه میشود: ردیابی کمکهای تامین اجتماعی. این پروژه راه را برای ظهور ماشینهای پردازش داده اولیه مانند کارت پانچهای IBM هموار کرد.
- دهه 1940: در طول جنگ جهانی دوم، نیاز به شکستن کدهای دشمن، بریتانیا را برای توسعه ابزارهای پردازش داده قدرتمند مانند کامپیوتر Colossus تحت فشار قرار داد.
- دهه 1960: IBM سیستمهای کامپیوتری را معرفی کرد که قادر به مدیریت مجموعه دادههای بزرگتری بودند. این موضوع نشاندهنده تغییری جدی به سمت تجزیهوتحلیل دادههای بزرگ بود.
ظهور پایگاه های داده و نرمافزار (دهه 1970-1990)
- دهههای 1970-1980: توسعه پایگاههای اطلاعاتی رابطهای و نرمافزار پردازش دادهها امکان سازماندهی و تجزیهوتحلیل بهتر مجموعه دادههای در حال رشد را فراهم میآورد.
ابداع اصطلاحات و ظهور پیشرفتهای تکنولوژیکی (دهه 1990-2000)
- دهه 1990: بحث در مورد اینکه چه کسی برای اولین بار از اصطلاح «Big Data» استفاده کرد، شروع شد. برخی جان مشی (John Mashey) را به خاطر عمومیت بخشیدن به این مفهوم، اولین میدانند، در حالی که برخی دیگر معتقدند این اصطلاح بعداً به وجود آمده است.
- سال 2005: یک سال کلیدی! راجر موگالاس و گروه رسانهای اوریلی با ابداع اصطلاح «Big Data» اعتبار پیدا کردند. در همین زمان بود که محدودیتهای ابزارهای داده سنتی در مدیریت حجم، تنوع و سرعت فزاینده اطلاعات نیز خود را نشان داد.
- سال 2005: یک نقطه عطف بزرگ دیگر! Apache Hadoop، یک چارچوب متن باز برای ذخیرهسازی توزیع شده و پردازش مجموعه کلان داده ها، منتشر شد. این چارچوب امکان مدیریت پیچیدگیهای بیگ دیتا را فراهم میکرد.
تأثیر کلان داده و فراتر از آن (دهه 2000 تا کنون)
- دهه 2000 به بعد: کلان داده ها به یک تغییردهنده بازی تبدیل میشوند و بخشهای مختلف جامعه مانند کسبوکار (بینش مشتری، بازاریابی هدفمند)، مراقبتهای بهداشتی (پزشکی شخصی، تحقیقات بیماری) و سرگرمی (سیستمهای توصیه، تولید محتوا) را تحت تاثیر قرار میدهند.
- حال: صحت داده ها (دقت، قابلاعتماد بودن) برای رسیدن به بینش قابلاعتماد، بسیار مهم میشود. فناوریهای جدید مانند رایانش ابری و هوش مصنوعی، تجزیهوتحلیل کلان دادهها را بیشتر تقویت میکنند.
مفهوم big data از چه اجزایی تشکیل شده است؟
امروزه سیستمهایی که دادههای بزرگ را پردازش و ذخیره میکنند، به جزئی جداییناپذیر در معماریهای مدیریت داده در سازمانها تبدیل شدهاند. اگرچه نمیتوان حجم مشخصی برای کلان دادهها در نظر گرفت، استقرار آنها اغلب در اندازههای ترابایت، پتابایت و حتی اگزابایت از دادههای ایجاد و جمعآوریشده در طول زمان است.
مفهوم کلان داده را اغلب با سه V مشخص میکنند:
- حجم (volume): حجم زیاد داده در محیطهای مختلف
- تنوع (Variety): طیف گستردهای از انواع داده ها
- سرعت (Velocity): سرعت بالایی که داده ها تولید، جمعآوری و پردازش میشوند.
حجم (Volume)، بزرگترین ویژگی کلان داده است. کلیکاستریمها، گزارشهای سیستم و سیستمهای پردازش جریانی از جمله منابعی هستند که معمولاً حجم عظیمی از دادهها را به صورت مداوم تولید میکنند.
از نظر تنوع (Variety)، کلان داده انواع مختلفی از داده ها را شامل میشود، از جمله:
- داده های ساختاریافته، مانند معاملات و سوابق مالی،
- داده های بدون ساختار، مانند متن، اسناد و فایلهای چندرسانهای،
- داده های نیمهساختاریافته، مانند گزارشهای وب سرور و جریان داده ها از حسگرها.
انواع داده های مختلف باید در سیستمهای کلان داده ذخیره و مدیریت شوند. علاوه بر این، سیستمهای شامل بیگ دیتا اغلب شامل مجموعهدادههای متعددی هستند که نمیتوانند از قبل یکپارچه شوند. بهعنوانمثال، یک پروژه تجزیهوتحلیل کلان داده ممکن است سعی کند فروش یک محصول را از طریق ایجاد همبستگی میان داده های مربوط به فروش گذشته و تماسهای خدمات مشتری پیشبینی کند.
سرعت (Velocity) به سرعتی اشاره دارد که داده ها با آن تولید شده و باید پردازش و تجزیهوتحلیل شوند. در بسیاری از موارد، مجموعههای کلان داده بهجای بهروزرسانیهای روزانه، هفتگی یا ماهانه که در بسیاری از انبارهای داده سنتی انجام میشود، بهصورت تقریباً واقعی بهروزرسانی میشوند. با گسترش تجزیهوتحلیل داده های بزرگ به یادگیری ماشین و هوش مصنوعی (AI) که در آن فرایندهای تحلیلی به طور خودکار الگوهایی را در داده ها پیدا میکنند و از آنها برای ایجاد بینش استفاده میکنند، مدیریت سرعت داده اهمیت بیشتری پیدا میکند.
با نگاهی فراتر از سه V اصلی، از دیگر ویژگیهای بیگ دیتا میتوان به موارد زیر اشاره کرد:
- صحت (Veracity): صحت به میزان دقت مجموعهداده ها و میزان قابلاعتماد بودن آنها اشاره دارد. دادههای خام جمعآوریشده از منابع مختلف میتواند باعث بروز مشکلاتی در تشخیص کیفیت دادهها شود. درواقع اگر دادههای نادرست از طریق فرایندهای پاکسازی داده رفع نشوند، منجر به بروز خطاهای جدی در تجزیهوتحلیل داده میشود که میتواند قابلیت اطمینان آنها را تضعیف کند. تیمهای مدیریت داده و تجزیهوتحلیل نیز باید اطمینان حاصل کنند که برای رسیدن به نتایج معتبر، داده های دقیق و کافی در دسترس قرار دارند.
- ارزش (Value): همه دادههای جمعآوریشده، ارزش یا آورده تجاری واقعی ندارند. در نتیجه، پیش از انجام هرگونه تحلیل کلان داده ها، سازمانها باید تأیید کنند که دادهها به مسائل کسبوکار مربوط میشوند و دارای ارزش تحلیل هستند.
- تغییرپذیری (Variability): تغییرپذیری اغلب در مورد مجموعهای از دادههای بزرگ به کار میرود که ممکن است معانی متعددی داشته باشند یا در منابع داده جداگانه قرار گیرند. این موارد میتوانند مدیریت و تجزیهوتحلیل بیگ دیتا را پیچیده کنند.
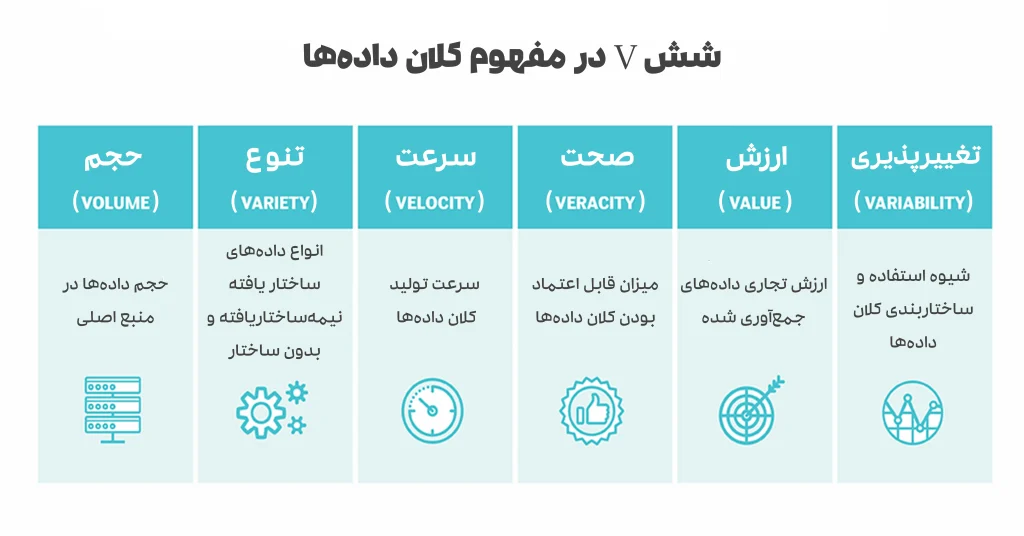
شش مفهوم اصلی در کلان داده ها
مزایای کلان داده ها
سازمانهایی که حجم دادههای بزرگ را به درستی استفاده و مدیریت میکنند، میتوانند از مزایای زیادی بهره ببرند، مانند:
- بهبود قدرت تصمیمگیری: کسبوکارها میتوانند بینشها، ریسکها، الگوها یا روندهای مهمی را از کلان داده ها به دست آورند. مجموعهدادههای بزرگ باید جامع باشند و اطلاعاتی را در بر بگیرند که سازمان برای تصمیمگیری بهتر به آنها نیاز دارد. بینشی که بیگ دیتا ایجاد میکند، به رهبران کسبوکارها اجازه میدهد تصمیمهای مبتنی بر داده و تأثیرگذاری برای سازمان خود اخذ کنند.
- کسب بینش بهتر نسبت به مشتری و بازار: کلان دادهها میتوانند روندهای بازار و عادات مصرفکننده را پوشش دهند. بهاینترتیب بینشهای مهمی را به سازمان ارائه میدهند که برای برآوردهکردن خواستههای مخاطبان موردنظر خود به آن نیاز دارند. بهویژه تصمیمات مرتبط با توسعه محصول، از این نوع بینش سود میبرند.
- صرفهجویی در هزینه: از بیگ دیتا میتوان برای مشخصکردن روشهایی که کارایی عملیاتی را افزایش میدهند، استفاده کرد. بهعنوانمثال، تجزیهوتحلیل کلان داده ها در مورد مصرف انرژی یک سازمان، میتواند به کارآمدتر شدن فعالیتهای آن کمک کند.
- تأثیر اجتماعی مثبت: بیگ دیتا را میتوان برای شناسایی مشکلات قابلحل، مانند بهبود مراقبتهای بهداشتی یا مقابله با فقر در یک منطقه خاص مورداستفاده قرار داد.
چالشهای کلان داده ها
از مهمترین چالشهایی که کارشناسان داده در مواجهه با بیگ دیتا با آنها مواجه هستند میتوان به موارد زیر اشاره کرد:
- طراحی معماری: طراحی یک معماری کلان داده با درنظرگرفتن ظرفیت پردازش سازمان، یک چالش رایج برای کاربران این داده ها است. سیستمهای کلان داده باید متناسب با نیازهای خاص سازمان باشند و مجموعهای از فناوریها و ابزارهای سفارشیسازی شده را کنار هم بگذارند.
- نیاز به تخصص: استقرار و مدیریت سیستمهای کلان داده، در مقایسه با مهارتهایی که مدیران پایگاهداده و توسعهدهندگان متمرکز بر نرمافزارهای رابطهای دارند، معمولاً نیازمند مهارتهای جدیدی است.
- هزینه: تحلیل بیگ دیتا نیازمند قدرت پردازشی بالایی است که استفاده از سرویسهای ابری مدیریت شده میتواند به کنترل این هزینههای زیرساختی کمک کند. در این حالت نیز مدیران فناوری اطلاعات همچنان باید استفاده از منابع را زیر نظر داشته باشند تا مطمئن شوند که هزینهها از کنترل خارج نمیشوند.
- مهاجرت: انتقال مجموعه دادهها و پردازش آنها در فضای ابر میتواند یک فرایند پیچیده و چالشبرانگیز باشد.
- دسترسی: یکی از چالشهای اصلی در مدیریت سیستمهای کلان داده، دسترسی به دادهها برای دانشمندان و تحلیلگران داده است؛ بهویژه در محیطهای توزیعشده که شامل ترکیبی از پلتفرمها و سیستمهای ذخیره داده مختلف است. برای کمک به این افراد در یافتن داده های مرتبط، تیمهای مدیریت و تجزیهوتحلیل داده، مدام در حال ساخت کاتالوگهای داده هستند که مدیریت ابردادهها را در خود جایداده است.
- ادغام: یکپارچهسازی مجموعههای بیگ دیتا نیز فرایندی پیچیده و پرچالش است؛ بهویژه زمانی که تنوع و سرعت دادهها عوامل تأثیرگذار هستند.

مدیریت موثر کلان داده ها در کسبوکار
کاربرد Big Data در کسبوکار
کسبوکارها میتوانند از کلان داده ها برای بهبود کارایی عملیاتی، ارائه خدمات بهتر به مشتریان، ایجاد کمپینهای بازاریابی شخصی و سایر اقداماتی که میتوانند درآمد و سود را افزایش دهند، استفاده کنند. بهاینترتیب سازمانهایی که از بیگ دیتا استفاده میکنند، نسبت به سایر کسبوکارها، مزیت رقابتی بالقوهای دارند؛ زیرا میتوانند تصمیمگیری سریعتر و آگاهانهتری داشته باشند.
بهعنوانمثال، داده های بزرگ بینشهای ارزشمندی در مورد مشتریان ارائه میدهد که شرکتها میتوانند از آنها برای اصلاح بازاریابی و تبلیغات خود برای افزایش تعامل با مشتری و نرخ تبدیل استفاده کنند. داده های تاریخی و بلادرنگ را میتوان برای ارزیابی ترجیحات در حال تغییر مصرفکنندگان یا خریداران تجزیهوتحلیل کرد و به کسبوکارها این امکان را میدهد تا به خواستهها و نیازهای مشتری پاسخ دهند.
محققان پزشکی از کلان داده ها برای شناسایی علائم بیماری و عوامل خطر و پزشکان برای کمک به تشخیص بیماریها و شرایط پزشکی در بیماران استفاده میکنند. علاوه بر این، ترکیبی از دادههای سوابق الکترونیکی سلامت، رسانههای اجتماعی، وبسایتها و سایر منابع آنلاین، میتوانند به سازمانهای مراقبتهای بهداشتی و سازمانهای دولتی، اطلاعاتی بهروز درباره تهدیدات و شیوع بیماریهای عفونی ارائه دهند.

شش مزیت بیگ دیتا برای کسبوکارها
از دیگر کاربردهای بیگ دیتا در صنایع مختلف میتوان به موارد زیر اشاره کرد:
- داده های بزرگ به شرکتهای فعال در حوزه نفت و گاز کمک میکند تا مکانهای حفاری احتمالی را شناسایی کرده و بر عملیات خط لوله نظارت داشته باشند. به همین ترتیب، شرکتهای فعال در حوزه برق میتوانند از بیگ دیتا برای ردیابی شبکههای برق استفاده کنند،
- شرکتهای ارائهدهنده خدمات مالی از سیستمهای کلان داده برای مدیریت ریسک و تجزیهوتحلیل بلادرنگ داده های بازار استفاده میکنند،
- تولیدکنندگان و شرکتهای حملونقل، برای مدیریت زنجیره تأمین خود و بهینهسازی مسیرهای تحویل به داده های بزرگ متکی هستند،
- سازمانهای دولتی از کلان داده ها برای واکنش اضطراری، پیشگیری از جرم و نوآوریهای شهر هوشمند استفاده میکنند.
بیگ دیتا چگونه ذخیره و پردازش میشود؟
کلان داده ها اغلب در یک دریاچه داده ذخیره میشوند. درحالیکه انباره های داده معمولاً روی پایگاههای داده رابطهای ساخته میشوند و فقط حاوی دادههای ساختاریافته هستند، دریاچههای داده میتوانند انواع مختلف داده را پشتیبانی کنند و معمولاً مبتنی بر خوشههای Hadoop، سرویسهای ذخیرهسازی اشیای ابری، پایگاههای داده NoSQL یا دیگر پلتفرمهای کلان داده هستند.
بسیاری از سیستمهای کلان داده، چندین سیستم را در یک معماری توزیع شده ترکیب میکنند. بهعنوانمثال، یک دریاچه داده مرکزی ممکن است با پلتفرمهای دیگر، از جمله پایگاه داده های رابطهای یا یک انبار داده، ادغام شود. دادهها در سیستمهای کلان داده ممکن است به شکل خام باقی بماند و سپس در صورت نیاز، برای استفادههای تحلیلی خاص، مانند هوش تجاری (BI)، فیلتر و سازماندهی شود. در برخی موارد نیز داده ها با استفاده از ابزارهای دادهکاوی و نرمافزارهای آمادهسازی داده، پیش پردازش شده و برای برنامههایی که به طور منظم اجرا میشوند، آماده میشوند.
پردازش کلان داده، نیازهای سنگینی را برای زیرساختهای محاسباتی ایجاد میکند که سیستمهای خوشهای اغلب این قدرت محاسباتی را فراهم میکنند. این سیستمها با استفاده از فناوریهایی مانند Hadoop و موتور پردازش Spark برای توزیع بارهای کاری پردازشی در صدها یا هزاران سرور، جریان داده را مدیریت میکنند.
رسیدن به این ظرفیت پردازشی به روشی مقرونبهصرفه، یک چالش جدی برای بسیاری از کسبوکارها است. بهترین راهحل برای این چالش، استفاده از فضای ابری برای پیادهسازی سیستمهای بیگ دیتا است. درواقع سازمانها میتوانند سیستمهای کلان داده و تحلیلهای خود را بر بستر ابر مستقر کنند یا راهکارهای نرمافزاری مبتنی بر ابر استفاده کنند. کاربران ابری میتوانند به تعداد موردنیاز خود، از سرورهای قدرتمند استفاده کنند و متناسب با حجم دادههای ذخیره شده و زمان استفاده از سرور، پرداخت انجام دهند.
معماری بیگ دیتا چیست؟
معماری کلان داده چارچوبی است از ابزارها و تکنیکهای مختلف که برای جذب، ذخیره، پردازش و تجزیهوتحلیل بیگ دیتا مورد استفاده قرار میگیرد. کلان دادهها به دلیل تنوع، سرعت تولید و حجم بالایی که دارند، بهسرعت درحالرشد هستند و بنابراین، یک پایگاه داده سنتی نمیتواند بهتنهایی آنها را مدیریت کند.
معماری بیگ دیتا این فرصت را برای کسبوکارها فراهم میکند تا از دادههای خود، درک و بینش لازم برای تصمیمگیری مؤثر را به دست آورده و ارزش داده ها را به حداکثر برسانند.
طراحی چارچوب معماری کلان داده به نیازها و اهداف منحصربهفرد کسبوکار بستگی دارد. این اهداف استراتژی معماری کلان داده مورد استفاده را تعیین میکنند، مانند اینکه کدام نوع تجزیهوتحلیل اجرا شود یا ایدهآلترین راه برای ذخیره داده ها چیست.
معماری کلان داده از مؤلفههای مختلفی برای ایجاد چارچوب استفاده میکند که از جذب، پردازش، ذخیرهسازی و تجزیهوتحلیل مجموعهدادههای عظیم پشتیبانی میکند. این چارچوبها شامل پایگاه های داده غیررابطهای است که امکان ذخیرهسازی داده های بدون ساختار را فراهم میکند. برخی از اجزای دیگر چارچوب معماری کلان داده عبارتاند از:
- منابع داده: منبع داده جایی است که مجموعههای کلان داده از آن بیرون کشیده شده و سپس وارد چارچوب معماری بیگ دیتا میشوند. منابع داده شامل رسانههای اجتماعی، وبسایتها و اینترنت است.
- ذخیرهسازی داده ها: ذخیرهسازی داده ها بخشی است که قادر به نگهداری مقادیر عظیمی از داده های ساختاریافته یا بدون ساختار است. ذخیرهسازی حجم زیادی از داده ها، چه ساختاریافته و چه بدون ساختار، اغلب بهعنوان دریاچه داده شناخته میشود.
- پردازش دستهای: پردازش دستهای یا batch processing فرایندی است که برای مرتبسازی و تبدیل کلان داده ها به فایلهای قابلاستفاده و آماده برای تجزیهوتحلیل انجام میشود.
- دریافت پیام بلادرنگ: این بخش از معماری کلان داده، داده ها را گروهبندی کرده و امکان انتقال آسانتر آنها به مراحل بعدی فرایند ذخیرهسازی را فراهم میکند. این مرحله امکان جذب و ذخیره جریان دادههایی را فراهم میکند که نیاز به پردازش در زمان واقعی دارند.
- پردازش جریانی: در این بخش، پیامهای بلادرنگ دریافت شده، آنها را فیلتر و برای تجزیهوتحلیل آماده میکند.
- ذخیرهسازی دادههای تحلیلی: در این قسمت است که دادههای پردازش و تمیز شده، برای استفاده توسط تکنیکها و ابزارهای تحلیلی مختلف در دسترس قرار میگیرند.
- تجزیهوتحلیل و گزارش: این مرحله بخشی از چارچوب معماری بیگ دیتا است که در آن، نرمافزار داده های تجزیهوتحلیل شده را برای رسیدن به بینش، الگوها و روندها بررسی میکند. در مرحله بعد، این نتایج به مکانیسم گزارش منتقل میشود و آنها را برای مشاهده انسان آماده میکند. بنابراین در این مرحله میتوان از اطلاعات ارائه شده، برای تصمیمگیری مؤثرتر در کسبوکار استفاده کرد.
- Orchestration: Orchestration فرایندی است که بهتمامی مراحل بالا اجازه میدهد تا به شکل خودکار اجرا شوند.
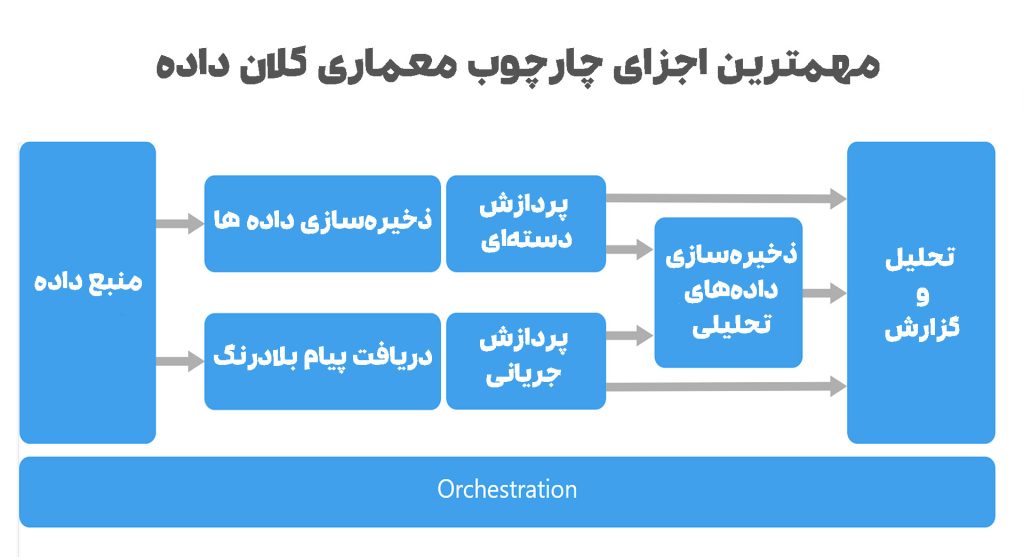
مهمترین اجزای چارچوب معماری بیگ دیتا
یک استراتژی کلان داده مؤثر چگونه است؟
توسعه یک استراتژی کلان داده مؤثر، مستلزم درک اهداف تجاری، داده های در دسترس و ارزیابی نیاز به داده های اضافی برای دستیابی به اهداف است. اقدامات بعدی که در این راستا باید انجام شود، شامل موارد زیر است:
- اولویتبندی موارد و کاربردهای برنامهریزیشده
- شناسایی سیستمها و ابزارهای جدید موردنیاز
- ایجاد نقشه راه استقرار
- ارزیابی مهارتهای داخلی
برای اطمینان از پاک بودن، سازگاری و استفاده صحیح از بیگ دیتا، باید برنامه حاکمیت داده و فرایندهای مدیریت کیفیت داده مرتبط نیز در اولویت قرار گیرند. تمرکز بر نیازهای کسبوکار به فناوریهای موجود و نمایش بصری داده ها، برای کمک به کشف و تجزیهوتحلیل داده ها از موارد دیگری است که در تدوین استراتژی کلان داده میتوان موردنظر قرارداد.

گامهای پیاده سازی استراتژی کلان داده در سازمان
آینده کلان داده ها
امروزه بسیاری از فناوریهای نوظهور بر نحوه جمعآوری و استفاده از دادههای بزرگ تأثیر میگذارند. فناوریهای زیر بیشترین تأثیر را بر آینده کلان داده خواهند داشت:
- هوش مصنوعی و یادگیری ماشین: کلان داده ها روزبهروز بزرگتر شده و به همان نسبت، قدرت انسان برای تحلیل آنها کمتر میشود. الگوریتمهای هوش مصنوعی و یادگیری ماشین در حال تبدیلشدن به یک راهحل کلیدی برای تجزیهوتحلیل در مقیاس بزرگ و حتی کارهای اولیه مانند پاکسازی و پیشپردازش داده ها هستند.
- ذخیرهسازی بهبودیافته با افزایش ظرفیت: قابلیتهای ذخیرهسازی ابری به طور مداوم در حال بهبود هستند. دریاچهها و انباره های داده بر بستر ابر، گزینههای جذابی برای ذخیره داده های بزرگ هستند.
- تأکید بر حاکمیت داده ها: با افزایش میزان استفاده از دادهها، حاکمیت و مقررات دادهها جامعتر و متداولتر میشوند و به تلاش بیشتری برای حفاظت و تنظیم آن نیاز است.
- محاسبات کوانتومی: اگرچه این فناوری کمتر از هوش مصنوعی شناخته شده است، اما محاسبات کوانتومی میتواند تجزیهوتحلیل داده های بزرگ را باقدرت پردازش بهبودیافته، تسریع کند. این فناوری در مراحل اولیه توسعه خود است و تنها برای شرکتهای بزرگ با دسترسی به منابع گسترده در دسترس است.
هوشمندی تجاری، راهکاری برای نمایش و تحلیل بهتر داده ها
کلان داده ها در عصر اطلاعات، به یک نیروی غیرقابلانکار تبدیل شده است که با استفاده از قدرت آن، میتوان تصمیمگیری را بهبود بخشید؛ از پزشکی تا بهینهسازی استراتژیهای کسبوکار، داده های بزرگ پتانسیل بسیار زیادی برای پیشرفت دارند.
نرم افزار BI با جمعآوری، تحلیل، تبدیل و تفسیر دادهها و تبدیل آن به اطلاعات قابل درک و اعتماد، همراه کسبوکارها در اخذ تصمیمهای هوشمندانه است. این راهکار طیف وسیعی از تحلیلهای آماده و KPIهای فرایندمحور را فراهم میکند که هزینه، زمان و ریسک پیادهسازی هوشمندی تجاری را به میزان قابلتوجهی کاهش میدهد. برای کسب اطلاعات بیشتر با ما در تماس باشید.
منابع:
- oracle.com
- learn.microsoft.com
- techtarget.com
- coursera.org
- mongodb.com


